Source Code or Machine Code?
The actual program which the runs in a CPU consists of instructions in machine code ; patterns of 0 and 1 stored in 14 bit chunks at different addresses. In the end, whatever means is used to achieve it, the machine code has to be placed in the right addresses for the CPU to run the instructions.
Human programmers find it difficult to write programmes in machine code; it is difficult to understand, difficult to read, difficult to remember. Instead, they may write in assembly language ; this will be represented as a list of ASCII characters, forming words and so on which are easier to understand, easier to read, easier to remember; but they correspond precisely to the instructions which the CPU executes, and can be translated into such instructions.
So, for example, INC COUNTER (which means, increase the value of the number stored in the register which has been given the label COUNTER" is easier to understand and remember than 00101010001100; even if this is written in Hex (0A8C) it may be easier to write, but no easier to understand. (A language like C is a little different; it also is represented by a string of ASCII characters; but each word or line usually does not correspond to a single instruction, but to a whole series of such instructions).
In order to be useful, assembly language has to be precise; there has to be no doubt how to translate the words into instructions; in order to do this, it is important to follow a set of rules for a particular language precisely.
Programming in C or Assembler
C is a ahigh-level language which is compiled rather than assembled. Although compilation is very complex, the basic operation resembles that of assembly:

Most programs are written in a "high level language" such as C, rather than assembler. However, for some specific tasks, assembler me be a more appropriate language.
Advantages of C
The same programme can be transferred to a different processor more easily.
Disadvantages of C
In practice, one can get many of the advantages of both worlds by using C for most of the program, and inserting sections of assembler (as external procedures) for key functions. Most C compilers allow this, and the linker is responsible for joining the various pieces of object code to form a single executable piece of amchine code.
The compiler takes as its source code a C program; this is a file of ASCII characters. It produces either an asembly language programme, as an intermediate step, or else machine code directly. Either way, the final result is machine code.
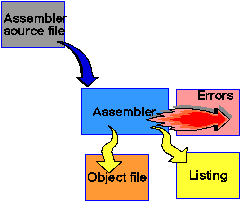
The assembler takes as its source code an assembly language
program; this is also a file of ASCII characters; it used this
to produce machine code.
Examples of assembly language programming are provided on a separate page.
Sometimes programmers choose to let others use the procedures which they have written, but do not want to give away the source code for their programs. One common way of doing this is to use a "library". Libraries are also useful when managing large projects which have many procedures, some of which are used by more than one program.
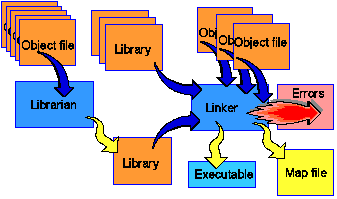
A library collects together pieces of object code for a specified set of procedures into a single file, and creates an index listing the procedures and position of each of the corresponding pieces of object code. Libraries are usually created by a library manager which accepts the object code generated by an assembler of compiler (acting instead of the linker).
When a programmer wishes to use a library, he informs the compiler/assembler by giving the name of the procedure (usually by using an "extern" directive to say it is an external procedure call) and sometiems the name of the library file. When the assembler/compiler finds a call to the procedure he requires is not a part of the current program. The compiler/assembler then doesn't try to find the address of the procedure, but instead leaves this to the linker. It provides the name of the appropriate libary file to the linker (or the linker searches through a previously set-up list of libraries).
The linker then processes the object code which was generated. It searches the known sets of library files. Each time it finds a procedure which matches one of the unresolved procedures in the object code it "links" a copy of the object code into the executable which it generates (i.e. it copies the appropriate object code byte by byte from the library). This is called "static linking". It fixes the executable code so that it will always run in the same way (even if the library files are no longer present on the computer).
In some cases, the programmer does not want the executable code
does to contain a copy of the libary procedure. This is called
"dyanmic linking". She/he may wish to use the
most recent version of the procedure that is available when the
program is run (which could be a long time after it was compiled).
This feature allows programmers to compile once, but take advantages
of the new features present in new versions of the libraries.
For instance, should a new graphics library be developed which
provides improved colours on the screen, a dynamically linked
program will immediately take advantage of the new library features.
When the linker performs a dynamic link, it requires the library to be present on the computer whenever the program is run. Instead of copying the code byte-by-byte at linking, the linker inserts a small piece of "stub" code which causes the executing program to find the library and copy the appropriate bytes into memory when required. Dynamic linking usually results in smaller executale programs. Sometimes programers choose to share teh same set of libraries between a numebr of simulatanbeously loaded programs - thsi can save considerabel amounts of memory and is usually the approach take by parts of the operating system.
Assemblers and Compilers allow the source code to contain instructions to the compiler/assembler to control the way in which it operates or to ask it to do specific tasks. These are called "directives" and so not necessarilly produce object code, as normal lines of program do.
The #define directive provides a way of giving telling the compiler/assembler, to replace a word by another word. The source file is searched for all ocurrences of the first word and each time a match is found, it is replaced by the second word. This provides a convienent way of typing commonly used labels or procedure names. It also allows the names to be changed later, should this be required.
For example,
#define z_bit status,2
may define the zero bit in the status register.
Wherever you code 'z_bit' in your program, the assembler will
interpret this as a reference to bit 2 of the status register.
The include directive simply copies a file containing source code from your current working directory; so you can put, for example, all the #defines, and so forth into a file called "defs.h" and, by using the directive
#include "defs.h"
you need never bother about writing these things again! #include directives may also be used to include previously written subroutines as a part of a new program. The #include directive effectively copies the contents of the named file into a copy of the source file, just prior to compilation.