
Memory: Addresses and data
The memory of a computer physically consists usually of a series of bits, each of which has a low or a high voltage. These bits are organised in groups of bits known as a word.
Words may be used to store data or instructions. A program consists of a series of words, each represents one "instruction" which corresponds to one elementary operation which the CPU can execute using an execution unit (e.g. the Integer Unit, Floating Point Unit, Branch Unit).
How does the CPU specify one particular instruction? It sends out an address to the memory (by placing the required value on the address bus). This is a binary number - a pattern of bits, each either 0 and 1 - which is put as a pattern of low and high voltages on a set of wires, connecting the CPU to the program memory.
The address bus specifies the memory location upon which the next operation will take place, in this case, where in memory the CPU will find the next instruction. When a word of memory is selected, the CPU sends a control signal to the memory to "read" the value stored at the location, which causes the memory to place the stored pattern of bits on the data bus, where it may be read by the CPU.
The register which stores the address of the next instruction is called the program counter. Usually after each instruction is executed, the program counter increases by one (hence the use of the word counter) so that it contains the address of the next instruction. Hence a program consists primarily of a list of instructions; and the program counter allows the CPU to step through the list, performing one instruction after another. Thus a hidden but implied part of every instruction is change the program counter to contain the address of the next instruction.
It is important to distinguish between the address at which an instruction is stored, and the contents of that address.
The CPU also contains registers in the Integer Unit which can be read from and written to. They are called general purpose registers.
There are also special purpose registers used for specific tasks:
PC Program Counter (points to next instruction)
IR Instruction Rgeister ("Value" of current instruction)
SR Status Register (Status flags after executing instructions)
SP Stack Pointer (points to next free location on the stack)
SF Stack Frame (used to locate program variables)
The program counter
The CPU contains a number of special purpose registers; the most important of these is called the program counter. The program counter contains the address of the next instruction.
The program counter is usually the same width (number of bits) as the address bus. It is quite common in computer systems to have more memory space than actual memory. If 13 only bits were used, the memory could contain 8K instructions. If 24 bits were used it could address 16 MB of memory.
Usually the contents of the program counter are automatically increased by 1 during every instruction. Thus the processor executes the instructions in a list one by one. There are other possibilities, to allow jumping (branching or procedure calls) to another part of the program. This is done by altering the contents of the program counter.
Data Memory
In addition to the memory in which the instructions are stored (program memory) there is also memory in which data is stored. The data memory is normally Random Access Memory (RAM) (or sometimes RWM, read/write memory) in contrast to the program memory which may be either RAM or ROM.
The most common way in which a program runs is from one instruction to the next in the memory.
address INST1 11 INST2 12 INST3 13 INST4 14
The program counter is automatically incremented by one after
each instruction so that the next instruction can be loaded. However
there are situations where you want to transfer the execution
of the program to somewhere else. For example, if you wanted to
make an endless loop for some purpose, in which the computer executed
the same set of instructions repeatedly, you would want to jump
back to the beginning. This means loading the program counter
with something different. We shall consider different ways of
controlling what the next instruction is; that is, controlling
the flow of the program.
see also Branch Instructions
Reading and Writing
If the CPU puts out an address, and then the contents of that address appear on the data lines (e.g. as an instruction) this is the operation of reading. (N.B. In a Harvard Architecture, the instructions in the program memory can only be read, they cannot be written; this memory is effectively ROM - Read Only Memory.)
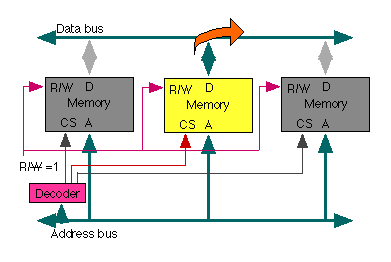
Two kinds of operation are possible; reading, in which the CPU specifies an address in the data memory, sets the Read/Write control wire to "read", and the data at that address appears on the data bus.
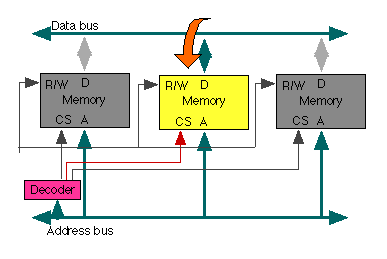
The CPU can also write data to the data memory; in this case the CPU specifies both the address and the data, and sets the Read/Write control wire to "write", the data is then written to the specified address. (Reading data corresponds to activating the Output Enable on the three state output of the CPU connected to the data bus; writing data corresponds to activating the Latch.
Harvard and von Neumann Architectures
There are two ways in which the computer memory used for storing instructions may be organised.
The program memory and the data memory may be quite separate (they could even use RAM with a different width e.g.14 bits for the program instructions, and 8 bits for the data) and different total numbers of addresses. This is an example of a Harvard architecture. It is used primarily by microcontroller CPUs.
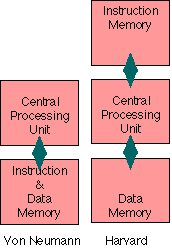
The other basic way of designing a computer, and by far the most common is to use one single memory system for both program and data. The address system is used for both the instructions (stored as one or two 16 bit numbers) which form the program, and for the data of various kinds (8 bit bytes or longer words). This is called the von Neumann architecture.
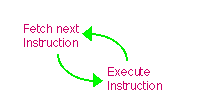
In a von Neumann architecture, the instruction has first to be fetched, using the program counter; then it can be executed. Since when the instruction is executed, it may also read or write data, you often cannot load one instruction and execute another at the same time. So the basic sequence in a von-Neuman architecture system is
fetch
execute
fetch
execute
This means that such a system may be slower. On the other hand, it has great advantages of flexibility, and the efficient use of memory caches can do a great deal to mitigate the apparent slowness of the architecture.
For example, what happens when you load up a game from disk into your computer? The program is stored as data, for example on a disc. You have to read that data, and store it in the memory of your computer. When you have done that, you can treat it as a program, (i.e. as a set of instructions) and run (execute) it. With a von Neumann architecture, since you have only one memory system, there is no problem; but with a Harvard architecture, you cannot do it - you cannot write data to the program memory - a special system is required to load the program into program memory.
The Harvard architecture also prevents you reading data from the program memory. For example, you may wish to include in your program tables of data, which can be used by the program; for example, messages to be displayed on the screen, or some kind of "look-up table". In a von Neumann architecture there is no problem; you can just store the table along with your program, and read it when you want to, because an instruction can read data from any address; in a Harvard architecture, data stored in the program memory cannot be read as data in the data memory. There are ways to get round this problem.
A von Neumann architecture is used for most computers; it allows the storing and running of different programs. A Harvard architecture is more appropriate for a microcontroller; in use, it will only ever run one program which will be stored in the ROM in its program memory. Moreover, the extra speed without the complexity of a sophisticated cache controller will be useful in some circumstances.
Pipelines
To speed operation of the CPU many computers use what is called a "pipeline system". What this means is that you divide up the operation of an instruction into separate parts, which have to be done one after the other; but you arrange that while one part of one instruction is being done, earlier parts of later instructions are being done. For example, consider a four stage pipeline; if each stage takes 100 nsec, then it takes a total of 400 nsec to completely process an instruction; but actually the throughput of the machine can be one instruction every 100nsec, since four different parts of four different instructions are being done at the same time.
So, while instruction one instruction is being executed, another is requesting the source data, the results of a previous operation are being written back, and another new instruction is being fetched.
RISC and CISC processors
These acronyms stand for "Reduced Instruction Set Computer" and Complex Instruction Set Computer". This gives a label to two different philosophies in designing computers. In a RISC processor, there are a fairly small number of fairly simple instructions. Each of these instructions does one simple operation, and at most one source value needs to be fetched from memory. In such a processor, the instructions can execute very rapidly. However, some operations require a whole series of instructions: for example, to multiply two eight bit numbers, there is no single instruction; you need a whole list of instructions.
In a CISC processor, one instruction can do a whole sequence of operations, , for example you can multiply two floating point numbers and add a third (a + b*c) all in one instruction; other processors do even more complex things in one instruction.
(N.B. Floating point units always operate over a variable number of clock cycles
Advantages of RISC:
Disadvantages of RISC